AWS/GCP Data Lake
Built a data lake on both GCP and AWS.
AWS
- Set connections to the datasources on AWS Glue.
- Built crawlers to populate the AWS Glue Data Catalog with tables.
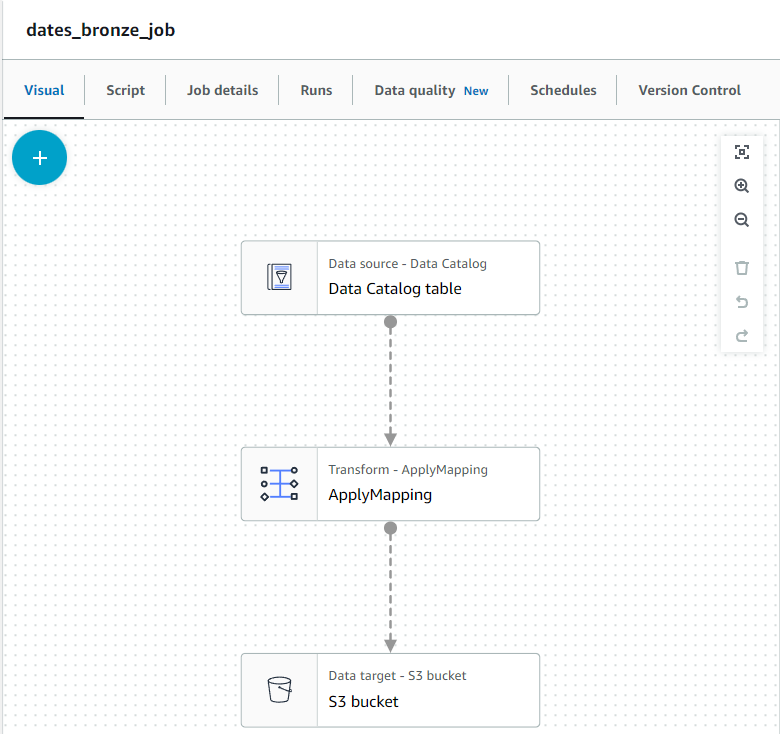
- Used Apache Spark to create AWS Glue Jobs to extract the created tables and store as raw Avro data on a S3 bucket.
- The raw data is then cleansed and refined to be sent to a S3 bucket as a Apache Parquet file.
- This is done because Parquet is a compressed optimized format for analysis.
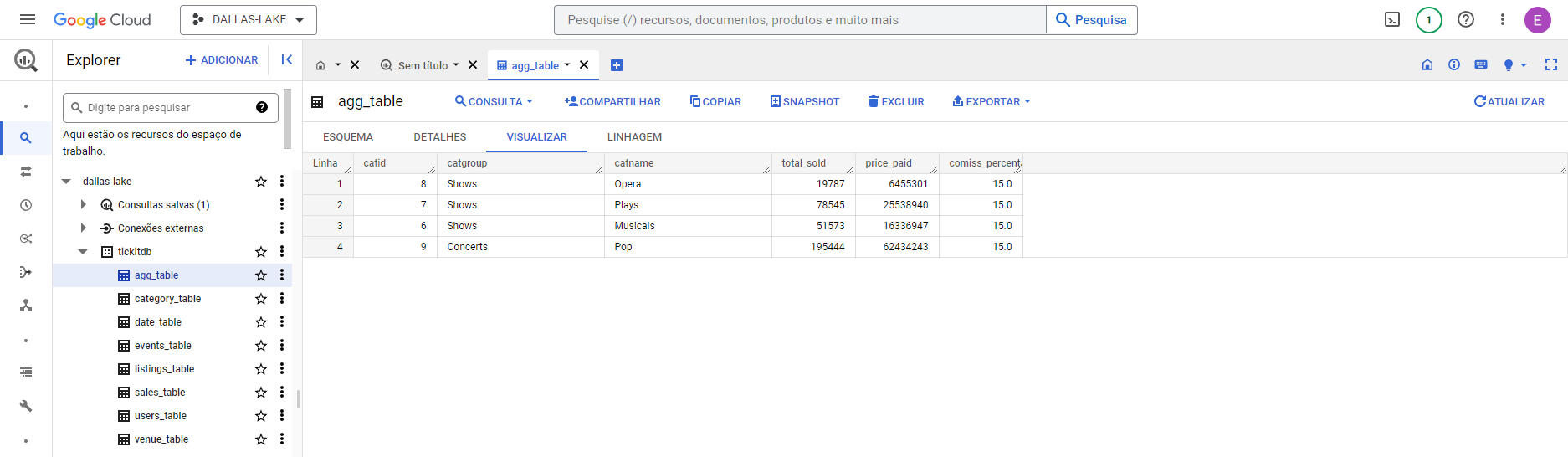
- Utilized AWS Athena to aggregate this new data to create custom viewes.
- In Athena, CTAS was used to write new data into a new partition on the S3 bucket.
- In this process, a few tables were aggregated to create new viewes.

GCP
- Created a bucket on Cloud Storage and uploaded the raw data as CSV.
- Created the dataset and tables on BigQuery from the uploaded data.
- Partitioned the tables creating new ones to get new views on the dataset.